Visibilidad de marca en packaging: qué aporta la IA y la atención visual
Introducción
La visibilidad de marca en packaging es uno de los factores más críticos en la relación entre la marca y el consumidor. El envase opera como un estímulo visual que organiza la mirada, jerarquiza la información y condiciona la primera impresión, incluso antes de cualquier lectura consciente. En el punto de venta físico o digital, donde decenas de productos compiten por un recurso escaso —la atención—, la manera en que un diseño distribuye sus elementos determina qué se percibe primero y qué pasa inadvertido. Dentro de ese conjunto, el logotipo ocupa un lugar singular: es el portador concentrado de la identidad de marca y el principal anclaje para el reconocimiento y el recuerdo.
La investigación en comportamiento del consumidor ha documentado de manera consistente que el diseño del envase influye en el reconocimiento de marca y puede asociarse con la intención de compra y las ventas (Shukla, Singh & Wang, 2022). Sin embargo, conviene establecer desde el inicio una distinción que recorrerá todo este artículo: que un logotipo sea visible no garantiza que la marca sea preferida, ni que el producto sea comprado. La visibilidad es una condición necesaria para el reconocimiento, pero no una causa suficiente de la decisión de compra. El valor de estudiar la visibilidad del logotipo reside en que opera en una etapa temprana del procesamiento visual, anterior a la deliberación, y por ello difícilmente accesible mediante la introspección del consumidor.
Este artículo examina cómo la inteligencia artificial —específicamente los modelos de detección de logotipos y de predicción de saliencia visual— puede contribuir a evaluar la visibilidad del logotipo en el diseño de envases. Se toma como fuente primaria el trabajo de Hosseini et al. (2025), publicado en Discover Applied Sciences, que propone un marco integrado de visión computacional para medir la prominencia de las marcas. La tesis central es que la visibilidad del logotipo debe entenderse como un problema medible de atención visual, y que los modelos de aprendizaje profundo pueden complementar —no sustituir— herramientas clásicas de la neurociencia del consumidor como el seguimiento ocular.
El problema científico: la visibilidad de marca como problema de atención
Abordar la visibilidad del logotipo con rigor exige separar conceptos que en el lenguaje cotidiano suelen confundirse. La visibilidad visual se refiere a la posibilidad física de que un elemento sea percibido dado su tamaño, contraste y posición. La saliencia designa la prominencia perceptual de una región: la probabilidad de que capte la mirada en función de sus propiedades de bajo nivel —color, luminancia, bordes— y de su contexto. La atención es el proceso cognitivo por el cual el sistema visual selecciona y prioriza determinada información; se manifiesta, entre otros indicadores, en las fijaciones oculares. El reconocimiento de marca implica que el consumidor identifica la marca a partir del estímulo, mientras que el recuerdo de marca supone recuperarla desde la memoria sin que el estímulo esté presente. Finalmente, la preferencia de marca y la intención de compra pertenecen al dominio actitudinal y decisional, e involucran factores que exceden por completo lo perceptual.
Estos niveles forman una cadena en la que cada eslabón es condición parcial del siguiente, pero ninguno lo determina mecánicamente. Un logotipo saliente tiene más probabilidad de ser atendido; un logotipo atendido tiene más probabilidad de ser reconocido y recordado; el reconocimiento facilita —pero no asegura— la preferencia. Confundir estos niveles conduce a inferencias inválidas, como suponer que aumentar la saliencia del logotipo elevará directamente las ventas.
Aquí reside la limitación de los métodos basados en autoinforme. Cuando se pregunta a un consumidor qué miró primero o qué le llamó la atención en un envase, su respuesta está mediada por la racionalización, la memoria reconstructiva y el deseo de coherencia. El procesamiento visual temprano ocurre en milisegundos y de forma mayoritariamente preatencional, fuera del alcance de la conciencia reflexiva. Por esta razón, la neurociencia del consumidor ha recurrido a métodos que miden la respuesta de manera directa y objetiva, evitando la dependencia de las preferencias declaradas (Hubert, Baecke & Kenning, 2008). El seguimiento ocular, al registrar dónde y por cuánto tiempo se fija la mirada, ofrece una ventana a estos procesos. El problema de la visibilidad de marca es, en definitiva, un problema de atención visual, y debe estudiarse con instrumentos capaces de capturarla.
Aportes del artículo
El trabajo de Hosseini et al. (2025) parte de una constatación práctica: analizar datos de seguimiento ocular sobre muestras amplias de personas es costoso y lento. De ahí la necesidad de modelos que reproduzcan el comportamiento atencional humano de manera escalable. Según los autores, no existía hasta entonces un método especializado en modelar la atención visual humana específicamente hacia los logotipos en envases. Su contribución es un marco integrado que combina tres componentes de visión computacional para cuantificar la prominencia de la marca.
El primer componente es la detección de logotipos mediante YOLOv8, un modelo de detección de objetos de última generación. Su función es localizar con precisión el logotipo dentro de la imagen, estableciendo la base para el análisis posterior. El segundo componente es un modelo de predicción de saliencia diseñado específicamente para el contexto de la publicidad y el envase, que incorpora de manera novedosa la influencia del texto en la generación del mapa de atención. El tercer componente integra los dos anteriores en un puntaje de atención de marca (brand attention score), una medida que estima cuánta atención capta el logotipo dentro de la composición visual total.
El valor de esta integración radica en situar la visión computacional al servicio de preguntas propias del marketing y la psicología cognitiva. Los autores no se limitan a proponer el marco: lo validan contrastándolo con estudios psicofísicos previos sobre visibilidad de marca, y reportan que el puntaje de atención resulta coherente con todos los hallazgos anteriores examinados (Hosseini et al., 2025). Sobre esa base, formulan siete nuevas hipótesis acerca del efecto de la posición, la orientación y otros elementos de diseño sobre la atención hacia la marca, explorando en total doce hipótesis de orden cognitivo.
Conviene leer esta contribución con precisión. El aporte es metodológico y predictivo: un sistema que estima la asignación probable de atención visual y la cuantifica de forma reproducible. No es un sistema que mida preferencia, actitud ni decisión de compra. Los propios autores enmarcan el trabajo como un avance en la intersección de la psicología cognitiva, la visión computacional y el marketing, posicionándolo como herramienta para investigar experimentos aún no explorados sobre logotipos en envases y publicidad. Es esta condición de herramienta de diagnóstico atencional, y no de oráculo comercial, la que define correctamente su alcance.
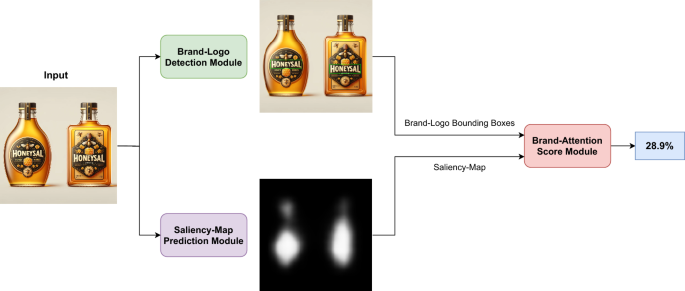
Figura 1 — Visión general del método de atención de marca propuesto, que articula los tres módulos: detección de logotipos, predicción de saliencia e integración en un puntaje de atención de marca.Fuente: Hosseini et al. (2025), Discover Applied Sciences · Licencia CC BY-NC-ND 4.0
Marco metodológico
El método propuesto se organiza en tres módulos encadenados, cada uno con una función técnica definida y una lectura práctica que conviene traducir a lenguaje accesible.
Primer módulo: detección de logotipos. El sistema emplea YOLOv8 (You Only Look Once, versión 8), un detector de objetos de una sola etapa entrenado específicamente para reconocer logotipos. Ante una imagen de entrada, el modelo devuelve una lista de cajas delimitadoras (bounding boxes), cada una definida por las coordenadas de sus esquinas, que encierran cada logotipo localizado. En términos llanos: el sistema "mira" el envase e indica con recuadros precisos dónde está exactamente la marca. Para entrenar el modelo, los autores utilizaron dos conjuntos de datos consolidados —FoodLogoDet-1500 y LogoDet-3K— que abarcan una amplia variedad de categorías de envases y marcas. Dado que para este propósito no interesa distinguir entre marcas sino detectar la presencia de cualquier logotipo, todas las clases se agregaron en una sola. El entrenamiento siguió un proceso de ajuste fino en dos etapas para resolver problemas de convergencia sobre conjuntos de datos de gran escala. En la comparación con otros métodos de referencia —entre ellos YOLOv7, Faster R-CNN, DETR y MFDNet—, YOLOv8 mostró un desempeño superior en métricas como precisión, exhaustividad (recall) y precisión media (mAP).
Segundo módulo: predicción de saliencia. Este es el componente más innovador del trabajo. El modelo se inspira en la red TranSalNet (Lou et al., 2022) e introduce mejoras orientadas a la eficiencia y al contexto específico de envases y publicidad. Su arquitectura combina una estructura CNN-Transformer y se compone de cinco partes principales. Primero, un detector de texto (DBNet++) identifica las regiones textuales de la imagen y genera un "mapa de texto", reconociendo que en los envases el texto compite por la atención tanto como los elementos gráficos. Segundo, un codificador CNN basado en la arquitectura ResNet-50 extrae características visuales de la imagen y del mapa de texto en distintas escalas espaciales, preservando la información de posición. Tercero, varios codificadores Transformer procesan esas características capturando relaciones de largo alcance dentro de la imagen; para reducir el costo computacional, el modelo adopta un mecanismo de atención eficiente que disminuye la complejidad respecto de la autoatención convencional. Cuarto, un bloque de fusión (Fusion Block) combina la información visual y la textual mediante un factor de ponderación que el propio modelo aprende durante el entrenamiento, en lugar de fijarlo de antemano. Quinto, un decodificador CNN reconstruye, a partir de la información fusionada y mediante conexiones de salto, el mapa de saliencia final a la resolución de la imagen original. El resultado es un mapa que asigna a cada región una probabilidad de captar atención visual. En lenguaje llano: el sistema produce un "mapa de calor" que estima hacia dónde es más probable que se dirija la mirada.
El modelo se entrenó sobre el conjunto SalECI, compuesto por 972 imágenes de comercio electrónico con sus mapas de fijación obtenidos mediante seguimiento ocular sobre 25 sujetos, sumando más de 257.000 fijaciones (Jiang et al., 2022). En la comparación con diez modelos de referencia, el método propuesto superó a las alternativas en todas las métricas evaluadas —CC, KL, NSS y SIM—, manteniendo un número competitivo de parámetros (Hosseini et al., 2025).
Tercer módulo: puntaje de atención de marca. Una vez localizado el logotipo y generado el mapa de saliencia, el sistema integra ambos. El procedimiento, descrito en el pseudocódigo del trabajo, convierte el mapa de saliencia en una lista de probabilidades por píxel que suma uno, descarta los valores por debajo de un umbral, normaliza el resto y suma las probabilidades correspondientes a los píxeles contenidos dentro de la caja del logotipo. El resultado es un puntaje que cuantifica qué proporción de la atención visual estimada recae sobre la marca. El mismo procedimiento puede aplicarse a cualquier objeto o texto cuya caja delimitadora se proporcione, no solo al logotipo, lo que extiende la utilidad del marco al análisis de otros elementos del diseño.
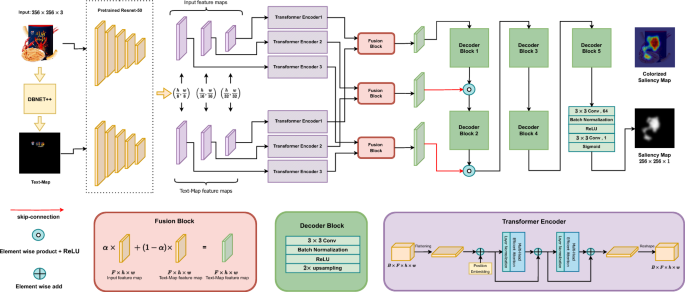
Figura 2 — Diagrama de bloques del modelo de saliencia propuesto, con sus cinco componentes principales: detector de texto, codificador CNN, codificadores Transformer, bloque de fusión y decodificador CNN.Fuente: Hosseini et al. (2025), Discover Applied Sciences · Licencia CC BY-NC-ND 4.0
Por qué los mapas de saliencia importan en la investigación de envases
Los mapas de saliencia mantienen una relación estrecha pero no idéntica con el seguimiento ocular. El seguimiento ocular registra el comportamiento real de la mirada de personas concretas: dónde se posan las fijaciones, en qué orden y durante cuánto tiempo. La predicción de saliencia, en cambio, estima computacionalmente la asignación probable de atención a partir de las propiedades de la imagen, sin que ningún ojo humano observe el estímulo en el momento de la predicción. Dicho de otro modo, el seguimiento ocular mide; el modelo de saliencia anticipa.
Esta distinción es decisiva para interpretar correctamente el aporte de la inteligencia artificial. Un modelo de saliencia bien entrenado puede aproximarse al promedio del comportamiento atencional de una población, porque ha aprendido regularidades a partir de datos de fijación reales —como ocurre con el conjunto SalECI, derivado de experimentos de seguimiento ocular—. Pero esa aproximación es estadística y poblacional: predice patrones agregados, no la conducta de un individuo particular ni la influencia de su estado motivacional, su familiaridad previa con la marca o el contexto de exposición.
De ello se desprende una consecuencia que conviene afirmar con claridad: los modelos de saliencia no reemplazan la medición conductual, biométrica ni de mercado. Estiman una probabilidad de atención bajo condiciones controladas, lo que los hace valiosos como instrumento de exploración rápida y de bajo costo, pero no como prueba definitiva de cómo se comportará un envase frente a consumidores reales en un anaquel real. Su lugar natural es el de un complemento que amplía la cobertura del seguimiento ocular y permite iterar antes de comprometer recursos en pruebas con personas.
Implicaciones prácticas para el neuromarketing y el diseño de envases
Trasladado a la práctica profesional, el marco propuesto habilita varias aplicaciones concretas en el diseño y la evaluación de envases.
La primera es el pretesteo de envases. Antes de someter un diseño a pruebas con consumidores, un equipo puede estimar mediante el modelo cuánta atención capta el logotipo y cómo se distribuye la saliencia sobre el conjunto del envase. Esto permite detectar de forma temprana diseños en los que la marca queda eclipsada por otros elementos, ahorrando tiempo y costo en etapas posteriores.
La segunda es la optimización del emplazamiento del logotipo. Dado que el sistema cuantifica la atención según la posición de la caja del logotipo, es posible comparar variantes de ubicación —superior frente a inferior, central frente a periférica— y observar cómo varía el puntaje de atención. La literatura previa que el propio artículo recoge sugiere efectos de la posición sobre la percepción de marca; el modelo ofrece una vía para examinar estas hipótesis de manera sistemática y reproducible.
La tercera es el análisis de jerarquía visual. Como el puntaje puede calcularse para cualquier elemento con caja delimitadora —logotipo, texto, imagen de producto—, el equipo de diseño puede verificar si el orden de prominencia visual coincide con el orden de importancia estratégica deseado. Si un elemento secundario domina la atención por encima de la marca, el diagnóstico lo revela.
La cuarta es la comparación entre alternativas de diseño. En lugar de decidir entre propuestas sobre la base de opiniones internas, el marco aporta una métrica común que permite contrastar versiones de forma objetiva, como insumo adicional para la deliberación creativa.
La quinta es el filtrado en etapa temprana mediante IA antes de la prueba con humanos. El modelo funciona como un primer tamiz que descarta las opciones manifiestamente débiles y concentra las pruebas de seguimiento ocular y los estudios conductuales en las variantes más prometedoras. Así se optimiza el uso de los recursos más costosos del protocolo de investigación.
Estas aplicaciones deben entenderse como implicaciones prácticas derivadas del marco, no como promesas de resultado comercial. El modelo informa sobre la atención visual estimada; la traducción de esa atención en reconocimiento, preferencia y, eventualmente, venta, depende de factores que el modelo no captura y que requieren su propia evidencia.
Evaluación crítica y limitaciones
El trabajo de Hosseini et al. (2025) es metodológicamente sólido y aborda un vacío real, pero su alcance tiene límites que un uso profesional responsable debe reconocer.
La primera limitación concierne a la validez externa. El modelo de saliencia se entrenó y evaluó sobre el conjunto SalECI, compuesto por imágenes de comercio electrónico y un número acotado de sujetos. El comportamiento atencional frente a una imagen en pantalla, en condiciones de laboratorio, no equivale necesariamente al de un consumidor en un anaquel físico, con iluminación variable, presión de tiempo, distracciones y competencia de productos vecinos. Extrapolar los resultados a contextos de compra reales exige cautela.
La segunda es la necesidad de validación humana. Aunque el puntaje de atención se contrastó con estudios psicofísicos previos, ningún modelo predictivo puede sustituir la verificación conductual y biométrica directa cuando hay decisiones de inversión en juego. La predicción computacional debe tratarse como hipótesis a confirmar, no como evidencia concluyente.
La tercera, y quizás la más importante, es el riesgo de confundir atención con preferencia o intención de compra. El marco mide visibilidad atencional. Que un logotipo atraiga la mirada no implica que genere agrado, confianza o disposición a comprar; un elemento puede ser saliente por resultar disonante o intrusivo. Interpretar un puntaje alto de atención como señal de eficacia comercial sería un error de inferencia que el propio diseño del estudio no autoriza.
La cuarta se refiere a las limitaciones de los datos. Los conjuntos empleados para la detección de logotipos y para la saliencia, aunque amplios, reflejan determinadas categorías de producto y estilos de diseño. Marcas con identidades visuales atípicas, envases de categorías poco representadas o logotipos integrados de manera no convencional podrían ser modelados con menor exactitud.
La quinta abarca los factores culturales y contextuales. La percepción del envase está mediada por hábitos de lectura, convenciones estéticas, significados cromáticos y expectativas de categoría que varían entre mercados. Un modelo entrenado sobre datos de una región o cultura no necesariamente generaliza a otras sin recalibración. Para mercados específicos —por ejemplo, los latinoamericanos—, la validación local sigue siendo indispensable.
En síntesis, las limitaciones no invalidan el aporte: lo sitúan. El marco es una herramienta de diagnóstico atencional poderosa dentro de su dominio, siempre que se la emplee con conciencia de sus fronteras.
Conclusión
La visibilidad del logotipo en el envase puede y debe tratarse como un problema medible de atención visual. El marco propuesto por Hosseini et al. (2025) demuestra que la inteligencia artificial —mediante la detección de logotipos, la predicción de saliencia y su integración en un puntaje de atención de marca— ofrece un instrumento riguroso, escalable y reproducible para diagnosticar cómo un diseño distribuye la atención y qué prominencia alcanza la marca.
Su valor más sólido, sin embargo, no reside en operar de forma aislada, sino en integrarse a un protocolo de investigación más amplio. Los modelos de atención basados en IA mejoran el diagnóstico del envase cuando se combinan con la predicción computacional para el filtrado temprano, el seguimiento ocular para la validación conductual de la mirada, los datos de mercado para verificar el impacto real y el juicio estratégico de marketing para interpretar todo ello a la luz de los objetivos de la marca. La IA no reemplaza al seguimiento ocular ni a la prueba con consumidores; los antecede, los focaliza y los hace más eficientes.
Entendida así, la propuesta marca un avance genuino en la intersección de la psicología cognitiva, la visión computacional y el marketing. La advertencia que debe acompañarla es la misma que ordena toda la cadena conceptual: la atención es el comienzo del proceso perceptual, no su desenlace comercial. Confundir el mapa con el territorio —la saliencia estimada con la decisión de compra— sería desaprovechar, por exceso de entusiasmo, lo que la herramienta sí puede ofrecer con solidez.
Referencias
Hosseini, A., Hooshanfar, K., Omrani, P., Toosi, R., Toosi, R., Ebrahimian, Z., & Akhaee, M. A. (2025). Brand visibility in packaging: A deep learning approach for logo detection, saliency-map prediction, and logo placement analysis. Discover Applied Sciences, 7(6), 537. https://doi.org/10.1007/s42452-025-07043-9
Hubert, M., Baecke, S., & Kenning, P. (2008). What they see is what they get? An fMRI-study on neural correlates of attractive packaging. Journal of Consumer Behaviour, 7(4–5), 342–359. https://doi.org/10.1002/cb.256
Jiang, L., Li, Y., Li, S., Xu, M., Lei, S., Guo, Y., & Huang, B. (2022). Does text attract attention on e-commerce images: A novel saliency prediction dataset and method. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2088–2097.
Lou, J., Lin, H., Marshall, D., Saupe, D., & Liu, H. (2022). TranSalNet: Towards perceptually relevant visual saliency prediction. Neurocomputing, 494, 455–467.
Shukla, P., Singh, J., & Wang, W. (2022). The influence of creative packaging design on customer motivation to process and purchase decisions. Journal of Business Research, 147, 338–347. https://doi.org/10.1016/j.jbusres.2022.04.026
Nota sobre las figuras. Las Figuras 1 y 2 proceden del artículo original de Hosseini et al. (2025), publicado bajo licencia Creative Commons CC BY-NC-ND 4.0, que permite la reproducción con atribución para usos no comerciales y sin obras derivadas. En caso de publicación con fines comerciales, podría requerirse permiso expreso del editor (Springer Nature) antes de su difusión.